|
Use this filter to find a text pattern. You can also use this filter to find
multi-line text.
The length of each string is shown above it, and a warning is displayed on
the status line if they are not the same.
This can be very useful when replacing strings in binary files.
Find pattern (perl-style)
The pattern to find. The right-click (or context) menu
on this field supports Undo, Cut, Copy, Paste, Delete, Clear Entire Field,
Select All and Select All And Copy, and entering unprintable and
special characters and inserting pattern match
characters.
See also
Pattern options button [...]
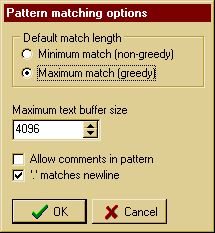
Default Match Length ("Greediness")
When set to maximal match, TextPipe will try to match the pattern against the
longest piece of text possible. When set to minimal match, TextPipe will try to
match the pattern against the shortest piece of text possible. Minimal matching
is the default and is the most often used, because it prevents the .* operator
from matching an end tag at the end of the file rather than the very next one,
and for this reason it is generally much faster than a maximal match. With a
large maximum text buffer size, greedy matching can be very inefficient.
This option inverts the "greediness" of the quantifiers so that they are not
greedy by default, but become greedy if followed by "?". It can also be set by a
(?U) option setting within the pattern.
Maximum Text Buffer Size
Changes the maximum search buffer size. If you need to match a string
that is longer than 4096 bytes (4k), increase the Maximum text buffer size to be
at least as large as the string you need to match.
Technical Notes:
The pattern matching engine is given a block of text to work with. This block
of text is guaranteed by TextPipe to be at least 4K larger than the size of the
"Maximum Text Buffer Size" - the block may be larger depending on what filters
precede the pattern match filter. Let's call
this buffer size the 'critical size'. This critical size allows for efficient
matching, because if the buffer is too large, the pattern matching engine may
have to check many cases before it fails, so it is more efficient to make it
fail earlier by having a smaller buffer size. If greedy matching is turned on,
having a larger buffer size may make matching very inefficient.
Allow Comments In Pattern
This enables Perl-style comments and extra white space to be included the
pattern match. White space data characters in the pattern are totally ignored
except when escaped or inside a character class, and characters between an
unescaped # outside a character class and the next new line character, inclusive,
are also ignored. This is very handy for including comments inside complicated
patterns. Note, however, that this applies only to data characters. White space
characters may never appear within special character sequences in a pattern, for
example within the sequence (?( which introduces a conditional sub pattern.
'.' Matches Newline
When enabled (default) a dot metacharacter in the pattern matches all
characters, including new lines. Without it, new lines are excluded. A negative
class such as [^a] always matches a new line character, independent of the
setting of this option.
Enable UTF-8 Support
Enables pattern matching in UTF-8 encoded data.
Match Case
When checked, the case of the string found must match the case of the Find
Pattern exactly.
Find Whole Words Only
Only match the Find Pattern when it is not part of a larger word e.g. find
"the" but not "them", "there", "worth" etc.
Replace With
The text to replace the found text with. The right-click (or context) menu on this field supports
Undo, Cut, Copy, Paste, Delete, Clear Entire Field, Select All and Select All And Copy,
entering unprintable and
special characters and inserting pattern replacement specifiers:
$0 - is replaced by the entire matched expression
$1 - is replaced with the first parenthesised expression.
$2 - is replaced with the second parenthesised expression
$3 - $9, $a - $z and so on.
If you need to put a dollar sign $ in the Replace With section, simply double
it i.e. $$.
The replacement text is passed to any sub filters.
Case Sensitive Replace
If the Find Pattern matches text that is entirely in UPPERCASE, this forces the replace
string to all UPPERCASE. If the Find Pattern matches text that is entirely in lowercase,
this forces the replace string to all lowercase.
Replace First Only
Only replace the first occurrence found - skip all remaining matches.
Prompt On Replace
By checking this option, you can manually verify each match before it gets
replaced. You can choose to replace or ignore single matches, the remainder of
the file or the entire job.
Skip Prompt If Identical
If the find string and replace string are identical, this option can be enabled to skip
prompting. This can happen when the case of the search string is identical to the case of
the replace string during a case-insensitive search.
Extract matches
When this option is checked all non-matching text will be discarded, leaving
only the replacement text. This can be handy for data mining content from web sites or
data files.
|